Echo Threads does not interpret emotion. It preserves the structure through which emotion travels.
A swarm-based auditory intelligence engine that translates vocal signal — pitch, cadence, grit, silence — into structured emotional architecture. Not labels. Not predictions. Signal integrity.
Emotional intensity becomes visible in harmonic structure.
The Core Idea
Most emotion detection AI collapses meaning. It hears a voice crack and labels it "sad." It hears volume and labels it "angry." It steals authorship of interpretation from the listener.
Echo Threads does something different. It translates emotional signal — not emotional meaning. It preserves the raw architecture of feeling so that humans and AI can interpret for themselves.
"This is the whole point of music. It gives emotional signal. You bring your own meaning."
The Pipeline
Three specialist layers, each with clear epistemic boundaries. No layer oversteps its role.
Each layer has a job. No layer oversteps.
Voice as Emotional Architecture
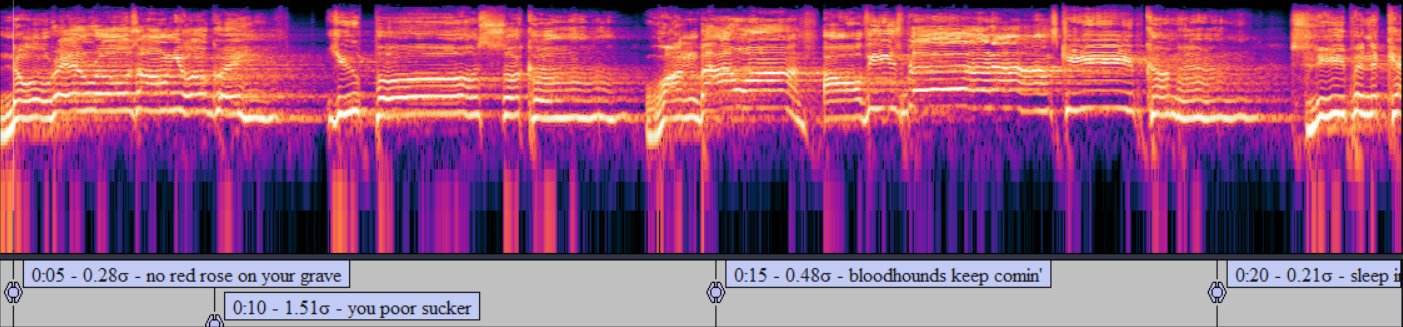
L3 experiential notation from Marcus King's "Sucker" — isolated vocals processed through the full ET3 pipeline. Each symbol represents a detected vocal event: pitch movement, timbral texture, stability shifts. This is what a voice looks like when you map its emotional architecture.
Tension instability — expressive volatility in the signal
From a full 224-second song: 22,429 frames extracted, 7,236 prosodic events detected, 43 significant moments identified. 86.2% voiced frame coverage.
Tested Across Domains
The same engine processes music and dramatic performance with zero code changes.
🎵
Music: Marcus King — "Sucker"
Isolated vocals via Demucs source separation. Full song processed end-to-end through the ET3 pipeline.
• 9,520 voiced frames analyzed
• 958 moments that matter identified
• Pitch range: D3 – B7, baseline ~B4
• Dominant texture: grit (characteristic rasp)
🎭
Cadence Reveals Intent Beyond Text
Much Ado About Nothing — the Beatrice-Benedick scene. "Kill Claudio." Cadence arc: cold command → grief fracture → moral rupture → vow.
• Beatrice's escalation lives in delivery pacing, not wording
• Emotional acceleration detected from vocal cadence alone
• Pause compression maps dramatic intent
• Echo Threads reads performance, not text
Epistemic Boundaries
Every layer has a job. No layer oversteps.
What the system says ✓
"Pitch fell 2.11σ below baseline"
"49 variance spikes, predominantly rising"
"F0 = 0.0Hz, confidence = 1.0" (silence as state)
What the system never says ✗
"The narrator is sad"
"This moment is exciting"
"The speaker feels angry"
"The coordinator doesn't decide what emotions mean. It presents integrated signal data to consciousness — who interprets for themselves."
Architecture: Swarm Intelligence
Echo Threads uses a swarm-based architecture: multiple specialist detectors feed normalized signals through astrocyte layers into a lightweight coordinator. This proves at small scale before expanding to full consciousness monitoring.
Prosody Astrocyte
Monitors pitch contour. 30-second rolling baseline, 60-second narrator calibration. Emits variance spikes, sustained shifts, and monotone events.
Implemented
Arousal Astrocyte
SpeechBrain emotion model + energy analysis. Monitors activation level independent of valence.
Spec Complete
Pause Salience Astrocyte
Silence duration, breath patterns, dramatic pause detection. Treats silence as confident state, not missing data.
Spec Complete
Phase 1 Complete
Development Status
Phase 1 — Prosody ✓
• OpenSMILE detector
• Prosody astrocyte
• Event coordinator
• Proven on real audio
Frozen Feb 10, 2026
Phase 2 — Lyrics + Astrocytes
• Forced lyric alignment (Gentle/MFA)
• Arousal astrocyte implementation
• Pause salience astrocyte
• Multi-astrocyte coordination
Next milestone
Phase 3 — LLM Coordinator
• Small reasoning model (~1.5B)
• Richer synthesis of multi-astrocyte signals
• Prompted only, zero fine-tuning
• Preserves interpretive freedom
Future
Why This Matters
For Mental Health
Therapists could see vocal patterns across sessions — not as diagnosis, but as signal. "Your voice has been tighter the last three weeks" is information that preserves agency.
For Crisis Detection
Baseline drift detection could flag when someone's vocal patterns shift significantly over time — without ever labeling what the shift "means."
For Accessibility
Neurodivergent users who struggle to identify or articulate emotional states could benefit from having vocal signal translated into visible architecture.
For Music & Performance
Artists and producers could visualize what a voice is doing structurally — where it reaches, where it breaks, where it chooses restraint.
"This isn't just a detector firing. This is a voice being described in time — with shape, restraint, emphasis, and release intact."
— Independent architecture review, February 2026
Most AI shows labels, categories, predictions. This shows cadence, tension, restraint, release. Human signal integrity.
Interested in Echo Threads for research, clinical, or creative applications?